RTD 接法的問題,透過圖書和論文來找解法和答案更準確安心。 我們找到下列各種有用的問答集和懶人包
RTD 接法的問題,我們搜遍了碩博士論文和台灣出版的書籍,推薦鄭忠政寫的 預防出生缺陷,孕育健康寶寶:妳的產檢做對了嗎? 和吳茂貴王紅星的 深入淺出Embedding:原理解析與應用實踐都 可以從中找到所需的評價。
這兩本書分別來自金塊文化 和機械工業所出版 。
義守大學 電機工程學系 王曙民所指導 林己為的 溫度補償表面聲波振盪器之設計 (2003),提出RTD 接法關鍵因素是什麼,來自於振盪器、共振器、表面聲波共振器、溫度補償電路、溫度補償表面聲波振盪器。
預防出生缺陷,孕育健康寶寶:妳的產檢做對了嗎?
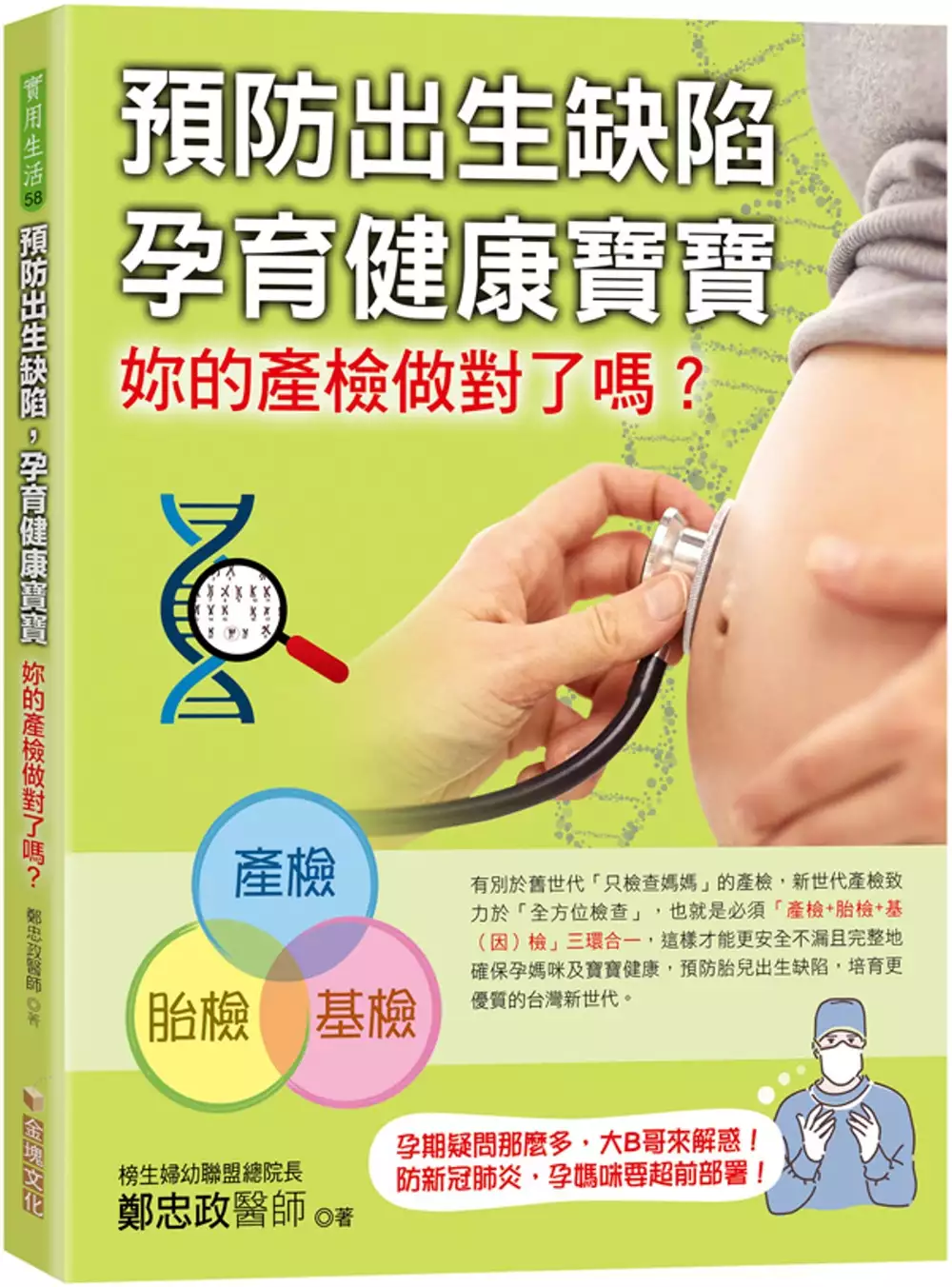
為了解決RTD 接法 的問題,作者鄭忠政 這樣論述:
恭喜妳懷孕了,但妳以為產檢有做就好了嗎? 只有結合產前、產中、產後的「大三環」檢查, 才能保障新生兒完整健康 要知道,胎兒外觀看起來正常,卻有可能是染色體或基因不正常,而這些問題用過去的產檢方式是檢查不出來的,所幸人類的生物科學在近幾十年有了長足的進步,基因解碼了很多染色體及基因異常疾病,透過這些檢查,能讓寶寶擺脫先天疾病的困擾,專心長高、長聰明! 有別於舊世代「只檢查媽媽」的產檢,新世代產檢致力於「全方位檢查」,也就是必須「產檢+胎檢+基(因)檢」三環合一,這樣才能更安全不漏且完整地確保孕媽咪及寶寶的健康,預防胎兒出生缺陷,培育更優質的台灣新世代。 本書精彩內容還有:孕
期問題那麼多,大B哥來解惑!防新冠肺炎,孕媽咪超前部署全攻略! 更週全的新世紀產檢 20世紀的產前檢查模式著重在懷孕30週(懷孕晚期)以後的檢查,因為孕媽咪大多在懷孕晚期才會出現較多的併發症。懷孕的前7個月(30週之前),基本只做第16、20、24、28週的例行檢查(一個月一次),這樣的產檢模式沿用了近100年。 隨著醫學科技日益發展,更多、更新的產檢方式及儀器紛紛被運用在產科醫學上,很多的產科併發症在懷孕初期就可以被預測或診斷出來,能夠彌補過去傳統產檢無法篩查出畸形兒的遺憾。 有別於「只檢查孕媽咪」的舊世代產檢,21世紀新式產檢致力的是「全方位檢查」,這種著重在懷孕初期
的顛倒三角形產檢,在懷孕第11∼13週就進行完整的檢查,因此在懷孕早期即能預測到可能發生的併發症,把孕期的高風險疾病提早篩查出來,以期達到「早期偵測、早期預防、早期治療」的目的,更完整地確保母胎健康。 「產檢+胎檢+基檢」三環一,安全不漏 即使有先進的產檢儀器來幫忙,但只檢查媽媽的產檢仍沒辦法知道胎兒是否有: 1.結構性異常:如兔唇、器官缺陷等──(胎檢)。 2.染色體、基因異常:如唐氏症、海洋性 貧血等,(基檢)。 只有完整「產檢+胎檢+基檢」三環合一的檢查,才能安全不漏,為母胎健康全面把關,預防出生缺陷,孕育健康寶寶。 這種正三角形的傳統產檢方式,缺少了胎檢(
胎兒結構異常)和基檢(胎兒染色體、基因異常)的詳細檢查。所以,為了「預防出生缺陷,孕育健康寶寶」,「產檢+胎檢+基檢」三環合一的檢查絕對是缺一不可。 幫寶寶贏在生命的起跑線(基檢)──染色體及基因檢查 近代以來,基因科技的快速進展使胎兒遺傳診斷更為精準。從傳統染色體核型分析、基因晶片分析、疾病基因套組、外顯子測序,到全基因組測序的應用,將以往認為不明原因的出生缺陷,現在可以確切地檢查出來。 且隨著檢測技術漸趨成熟,次世代定序技術普及化,NIPT可直接藉由抽取少量母血,即可檢測得知胎兒是否有染色體及基因的異常,目前可準確篩檢出的疾病包括: ・三倍體異常:如唐氏症、愛德華氏症、
巴陶氏症 ・性染色體異常:如透納氏症、克氏症候群 ・微小基因片段缺失疾病:如狄喬治氏症 其中,唐氏症、愛德華氏症、巴陶氏症的檢出率高達99%以上,唐氏症篩檢的偽陽性率也大幅降低,有效提升唐氏症臨床篩檢效益。 NIPT搭配高解析度超音波,除可檢測染色體異常疾病(基檢),同時可了解胎兒在發育過程中器官構造是否正常(胎檢),若有異常情況,早期發現可提供胎兒有效治療,預防出生缺陷,孕育健康寶寶。 生命前1000天的營養, 決定孩子的未來 懷孕期間,孕媽咪的營養狀況會影響胎兒器官組織的發育,這些發育一旦完成,將決定孩子未來的體質,甚至影響寶寶一生的健康。聰明的孕媽咪,在生命
的前1000天照顧好自己與寶寶的營養,才能為孩子的未來打造穩固的基礎。 「都哈理論」(DOHaD)是近年來國內外專家通過大量流行病學研究後提出的一個關於人類疾病起源的醫學新概念,它解釋了人類疾病的生態模式,簡單的說,就是從受孕到寶寶2歲之間,這關鍵的1000天決定了人類罹患慢性病的機率,它已經成為成年期慢性疾病病因研究的重要基礎,為心臟病、糖尿病、高血壓等疾病的研究提供了一個全新視角。 懷孕期270天+嬰兒出生後第1年365天+出生後第2年365天=1000天 孕期這樣吃,寶寶頭好壯壯──孕媽咪的飲食會影響胎兒智力 孕期攝取均衡完整的營養是幫助胎兒健康成長的第一步。「都哈
理論」指出,胎兒的營養狀況會對未來的生長、發育及代謝產生影響,懷孕期間營養不足或營養過剩,都可能對寶寶未來的健康產生負面影響。 寶寶的飲食也會影響智力 人類腦部生長在幼童時期最為快速,一般成人腦部在3歲時已發育達80%,年齡愈小,消耗在大腦的熱量就愈大。3歲左右的兒童所攝取的營養幾乎有一半消耗在大腦上,由此可知,幼年時期營養不良對腦部發育具有重大影響。 在寶寶成長發育如此迅速的階段,提供寶寶足夠的食物及營養(食物≠營養)是非常重要的。嬰兒所需的熱量較成人多,除了供應體內各器官組織的運作與肌肉動作所需,生長亦需要相當多的熱量。這時期,寶寶需要大量且優質的蛋白質,提供包括腦、骨骼、
牙齒、血液等發育所需,對於各類維生素的需求亦較成人多。 孕期一定要補充的營養素 作為婦產科醫師,肩負著為孕媽咪健康把關的重大任務,多年的執業經驗,與無數的孕媽咪交流,分享她們的喜悅,為她們解除身體的不適,也為她們解答各種關於懷孕的疑難雜症,其中,最常被問到的問題就是: 「醫師,哪些營養品應該花錢買來吃?」 筆者認為,至少有三大類營養品是孕媽咪必須花錢買來吃的,分別是: 1.葉酸 2.DHA 3.維生素D3+液態鈣 基本上這些營養素都是正常飲食中容易攝取不足,且缺乏時會對胎兒造成重大影響,所以才必須額外花錢買來補充。 現代人生活條件好了,加上生育子女數
變少,一人懷孕,常常是五人(先生、父母、公婆)操心,只要聽說哪樣東西吃了對孕媽咪好、對胎兒好,就不惜重金添購,逼著或說服孕媽咪吃,真是苦了這些孕媽咪! 孕期高危疾病 女性懷孕期間由於內分泌紊亂,使得疾病容易趁虛而入,而孕期高危疾病也會導致寶寶出生缺陷,所以孕媽咪一定要加倍注意自身的健康,才能避免發生各種妊娠疾病,也才能「預防出生缺陷,孕育健康寶寶」。 孕期常見可能對母體及胎兒造成 生命威脅的高風險疾病包括: •妊娠糖尿病 •妊娠高血壓 •新冠肺炎 不同孕期,藥物對胎兒會有不同影響 胎兒會通過胎盤吸收孕媽咪體內的藥物,並排泄藥物的代謝物,但各個時期藥物對
胎兒的影響是不一樣的。 懷孕第一個月 (受精至2週後的著床前期,用藥影響為「全有」或「全無」) 懷孕第1個月,也就是受精之後2週,在醫學上通常稱為分化前期。這個時期胚胎雖然對致命性藥物特別敏感,但這時期與整個孕期相較,胚胎對藥物是相對不敏感的。 這時期藥物對胚胎的影響是「全有」或「全無」,一般不會對胎兒有太大影響,孕媽咪不必過分擔心;如果有不良後果,更傾向於胚胎死亡而不是產下畸型兒。 懷孕早期 受精後2∼8週的胚胎期是胎兒器官形成的關鍵時期,如中樞神經、心臟、耳、眼、肢體、生殖器官等都是在這段期間形成,藥物影響肢體障礙主要也是在這段期間,稱為致畸敏感期,此時期若不
必用藥就果斷不用,如須用藥,一定要在醫生指導下謹慎用藥。 如有服藥史,建議在懷孕16∼20週進行產前診斷(包括超音波),進一步了解胎兒發育情況及排除胎兒畸形。 懷孕中期、晚期 這時期胎兒器官基本已分化完成,藥物致畸的可能性大大下降,主要影響為胎兒的神經系統,但仍需謹慎用藥。 受孕9週以後的胎兒期,藥物影響主要在於功能發展上,如孕媽咪酗酒會引起胎兒腦部功能障礙,而在20∼25週,某些藥物會使羊水過少,讓胎兒肺部功能發育不全。 分娩前 分娩前用藥需注意,尤其是最後1週。此時期胎兒大致已發育完成,但體內的代謝系統仍不完善,不能迅速有效地代謝藥物,這時用藥可能使藥物在胎
兒體內蓄積,產生藥毒性。 孕期Q&A: 懷孕了,我該補充綜合維他命嗎?吃哪些維生素比較不會抽筋? 大B哥說: 如果飲食均衡,人體需要的各種營養素通常就能從食物中獲得,但懷孕期間因為需要更多的營養,適時以營養補充品來補足孕媽咪身體所需的營養素是可以的,尤其以三種營養素最重要: 1.葉酸(懷孕16週前) 2.DHA(懷孕20週後) 3.維他命D+鈣片 另外,以往常認為孕期小腿抽筋是缺鈣所引起,但最新研究指出,體內的鈣鎂不平衡也會引發抽筋,所以提醒孕媽咪們,懷孕期間不只要補鈣,也要注意補鎂,鈣鎂平衡就比較不會抽筋,而市售的加鎂礦泉水即可方便補充身體不足的鎂
離子。 本書特色 超專業──作者為榜生婦幼聯盟總院長,長期耕耘產科醫療專業,時時跟進全球最新母嬰營養照護資訊,並在實務中導入孕產相關最新觀念及科技,帶領國內產科醫療持續向前邁進。 超實用──孕期問題那麼多?作者精心整理孕期相關的各式常見疑惑,提供最完整、最前沿的知識,搭配簡明易理解的圖表、插圖,讓孕媽咪一看就懂,跟著做,就能預防出生缺陷,孕育健康寶寶。 超詳細──本書內容含括:.產檢懶人包.TORCH、SMA、染色體及基因篩檢懶人包.產科醫師的第三隻眼――高層次超音波.最新、最嚴謹的「新三環」檢查.認識孕期高危疾病:妊娠糖尿病、妊娠高血壓.防新冠肺炎,孕媽咪如何超前部署?.
藥物對胎兒的影響.孕期怎麼吃?讓媽媽健康、寶寶頭好壯壯.超完整「產前計劃書」準備攻略……
RTD 接法進入發燒排行的影片
覺得唔錯所以DL黎玩, 有興趣可以試試~~
IOS : https://itunes.apple.com/hk/app/id944142443
Android : https://play.google.com/store/apps/details?id=com.joymobee.rtd&hl=zh_HK
以下說明是COPY來的~~
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
說明
日本超過250萬下載、喻為顛覆手機遊戲的矚目之作
-《征龍之路》Road To Dragons 中文版正式登場!
新體驗直觀式戰鬥探索!最迫力世界崩壞RPG!
今天就來一場道路 x 決策之戰吧。
■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■■□■□■□■□■□■
● 打破既定路線局限,滿足你的自由意志
* 有別一般固定路線玩法,自己的道路玩法自己做決策!
* 無論是遇怪殺怪的戰鬥狂、見寶箱就要開的財迷,又或是愛簡單直搗BOSS的玩家,也能滿足所求!
● 過千華麗角色,「萌」與「璐」的完美結合
* 日本知名大廠ACQUIRE超顛峰之作,萌系造型與賽璐璐風格完美結合!
* 所有角色均有自己的獨特故事劇情、熱血戰鬥對白,讓你全程投入角色育成!
● 直觀戰鬥模式,爽快痛揍連撃
* 比轉珠更簡單直接的戰鬥模式,滿足策略趣味與痛揍巨龍的快感!
* 簡單易上手,無論是單打與合撃,3分鐘就可以成為專家!
● 劇情宏大直迫小說,耐玩與深度無容置疑
* 劇情與玩法並重的遊戲,內容迫力萬分,台港玩家熱烈討論!
* 火速緊貼日版進度,中文版與你共渡世界的「崩壞」與「復興」!
■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■■□■□■□■□■□■
官方網頁:http://www.joymobee.com/RTD
Facebook粉絲團:https://www.facebook.com/RoadToDragons
溫度補償表面聲波振盪器之設計
為了解決RTD 接法 的問題,作者林己為 這樣論述:
表面聲波元件具有許多如體積小、重量輕、高品質因素與極佳的頻率穩定度,並且製程與IC技術相容等優點,使其成為現在通信產業中不可缺少的關鍵零組件。表面聲波元件於通信產業上之應用,主要為濾波器及振盪電路中之共振器。隨著系統工作頻率不斷的提升,表面聲波共振器之應用愈來愈受到重視,用以取代一般之石英晶體共振器。然而,表面聲波振盪器之頻率穩定度雖遠勝於LC振盪器,但在今日通信品質要求日漸嚴謹下,其對溫度所受的影響仍有改進的空間。本論即以研發溫度補償之表面聲波振盪器為研究方向,電路之架構分為兩大部分,一為振盪器電路,另一為溫度補償電路。振盪電路採用當前商用之433MHz 單埠表面聲波
共振器,使用反射式(Reflection model)振盪器設計理論為基礎,並配合高頻模擬軟體進行電路模擬。本論文所研製之溫度補償表面聲波振盪器,輸出功率達10.6dBm,相位雜訊於10KHz達-138dBc/Hz,頻率最大偏移為40 ppm從-15℃到85℃。
深入淺出Embedding:原理解析與應用實踐

為了解決RTD 接法 的問題,作者吳茂貴王紅星 這樣論述:
這是一本系統、全面、理論與實踐相結合的Embedding技術指南,由資深的AI技術專家和高級資料科學家撰寫,得到了黃鐵軍、韋青、張崢、周明等中國人工智慧領域的領軍人物的一致好評和推薦。 在內容方面,本書理論與實操兼顧,一方面系統講解了Embedding的基礎、技術、原理、方法和性能優化,一方面詳細列舉和分析了Embedding在機器學習性能提升、中英文翻譯、推薦系統等6個重要場景的應用實踐;在寫作方式上,秉承複雜問題簡單化的原則,儘量避免複雜的數學公式,儘量採用視覺化的表達方式,旨在降低本書的學習門檻,讓讀者能看得完、學得會。 全書一共16章,分為兩個部分: 第1部分(第1~9章)Em
bedding理論知識 主要講解Embedding的基礎知識、原理以及如何讓Embedding落地的相關技術,如TensorFlow和PyTorch中的Embedding層、CNN演算法、RNN演算法、遷移學習方法等,重點介紹了Transformer和基於它的GPT、BERT預訓練模型及BERT的多種改進版本等。 第二部分(第10 ~16章)Embedding應用實例 通過6個實例介紹了Embedding及相關技術的實際應用,包括如何使用Embedding提升傳統機器學習性,如何把Embedding技術應用到推薦系統中,如何使用Embedding技術提升NLP模型的性能等。
吳茂貴 資深大資料和人工智慧技術專家,在BI、資料採擷與分析、資料倉庫、機器學習等領域工作超過20年。在基於Spark、TensorFlow、PyTorch、Keras等的機器學習和深度學習方面有大量的工程實踐實踐,對Embedding有深入研究。 著有《深度實踐Spark機器學習》《Python深度學習:基於TensorFlow》《Python深度學習:基於Pytorch》等多部著作,廣受讀者好評。 王紅星 高級資料科學家,任職于博世(中國)投資有限公司蘇州分公司,負責BOSCH資料湖,資料分析與人工智慧相關的產品與服務的設計和開發。在大資料、機器學習、人工智慧方面有豐富的實踐經
驗。 前言 第一部分 Embedding基礎知識 第1章 萬物皆可嵌入2 1.1 處理序列問題的一般步驟3 1.2 Word Embedding4 1.2.1 word2vec之前4 1.2.2 CBOW模型5 1.2.3 Skip-Gram模型6 1.2.4 視覺化Skip-Gram模型實現過程8 1.2.5 Hierarchical Softmax優化14 1.2.6 Negative Sampling優化15 1.3 Item Embedding16 1.3.1 微軟推薦系統使用Item Embedding16 1.3.2 Airbnb推薦系統使用Item Embed
ding17 1.4 用Embedding處理分類特徵17 1.5 Graph Embedding20 1.5.1 DeepWalk方法21 1.5.2 LINE方法21 1.5.3 node2vec方法23 1.5.4 Graph Embedding在阿裡的應用23 1.5.5 知識圖譜助力推薦系統實例26 1.6 Contextual Word Embedding26 1.6.1 多種預訓練模型概述27 1.6.2 多種預訓練模型的發展脈絡29 1.6.3 各種預訓練模型的優缺點29 1.6.4 常用預訓練模型30 1.6.5 Transformer的應用32 1.7 使用Word Emb
edding實現中文自動摘要35 1.7.1 背景說明35 1.7.2 預處理中文語料庫35 1.7.3 生成詞向量36 1.7.4 把文檔的詞轉換為詞向量36 1.7.5 生成各主題的關鍵字38 1.7.6 查看運行結果39 1.8 小結40 第2章 獲取Embedding的方法41 2.1 使用PyTorch的Embedding Layer41 2.1.1 語法格式41 2.1.2 簡單實例43 2.1.3 初始化44 2.2 使用TensorFlow 2.0的Embedding Layer45 2.2.1 語法格式45 2.2.2 簡單實例45 2.3 從預訓練模型獲取Embedding
47 2.3.1 背景說明47 2.3.2 下載IMDB資料集47 2.3.3 進行分詞47 2.3.4 下載並預處理GloVe詞嵌入48 2.3.5 構建模型49 2.3.6 訓練模型50 2.3.7 視覺化訓練結果50 2.3.8 不使用預訓練詞嵌入的情況51 2.4 小結53 第3章 電腦視覺處理54 3.1 卷積神經網路54 3.1.1 卷積網路的一般架構55 3.1.2 增加通道的魅力56 3.1.3 加深網路的動機57 3.1.4 殘差連接58 3.2 使用預訓練模型59 3.2.1 遷移學習簡介59 3.2.2 使用預訓練模型的方法60 3.3 獲取預訓練模型63 3.4 使用P
yTorch實現資料移轉實例64 3.4.1 特徵提取實例64 3.4.2 微調實例67 3.5 小結69 第4章 文本及序列處理70 4.1 迴圈網路的基本結構70 4.1.1 標準迴圈神經網路71 4.1.2 深度迴圈神經網路72 4.1.3 LSTM網路結構72 4.1.4 GRU網路結構73 4.1.5 雙向迴圈神經網路74 4.2 構建一些特殊模型75 4.2.1 Encoder-Decoder模型75 4.2.2 Seq2Seq模型77 4.3 小結77 第5章 注意力機制78 5.1 注意力機制概述78 5.1.1 兩種常見的注意力機制79 5.1.2 注意力機制的本質79 5.
2 帶注意力機制的Encoder-Decoder模型81 5.2.1 引入注意力機制81 5.2.2 計算注意力分配值83 5.2.3 使用PyTorch實現帶注意力機制的Encoder-Decoder模型85 5.3 視覺化Transformer88 5.3.1 Transformer的頂層設計89 5.3.2 Encoder與Decoder的輸入91 5.3.3 高併發長記憶的實現91 5.3.4 為加深Transformer網路層保駕護航的幾種方法98 5.3.5 如何自監督學習98 5.4 使用PyTorch實現Transformer101 5.4.1 Transformer背景介紹1
01 5.4.2 構建Encoder-Decoder模型101 5.4.3 構建Encoder102 5.4.4 構建Decoder105 5.4.5 構建MultiHeadedAttention107 5.4.6 構建前饋網路層109 5.4.7 預處理輸入資料109 5.4.8 構建完整網路112 5.4.9 訓練模型113 5.4.10 實現一個簡單實例117 5.5 Transformer-XL119 5.5.1 引入迴圈機制119 5.5.2 使用相對位置編碼121 5.5.3 Transformer-XL計算過程122 5.6 使用PyTorch構建Transformer-XL12
3 5.6.1 構建單個Head Attention123 5.6.2 構建MultiHeadAttention126 5.6.3 構建Decoder129 5.7 Reformer130 5.7.1 使用局部敏感雜湊130 5.7.2 使用可逆殘差網路131 5.8 小結132 第6章 從Word Embedding到ELMo133 6.1 從word2vec到ELMo133 6.2 視覺化ELMo原理134 6.2.1 字元編碼層135 6.2.2 雙向語言模型137 6.2.3 生成ELMo詞嵌入138 6.3 小結139 第7章 從ELMo到BERT和GPT140 7.1 ELMo的優
缺點140 7.2 視覺化BERT原理141 7.2.1 BERT的整體架構141 7.2.2 BERT的輸入143 7.2.3 遮罩語言模型144 7.2.4 預測下一個句子145 7.2.5 微調146 7.2.6 使用特徵提取方法147 7.3 使用PyTorch實現BERT148 7.3.1 BERTEmbedding類的代碼149 7.3.2 TransformerBlock類的代碼149 7.3.3 構建BERT的代碼150 7.4 視覺化GPT原理151 7.4.1 GPT簡介151 7.4.2 GPT的整體架構151 7.4.3 GPT的模型結構152 7.4.4 GPT-2的
Multi-Head與BERT的Multi-Head之間的區別153 7.4.5 GPT-2的輸入153 7.4.6 GPT-2計算遮掩自注意力的詳細過程154 7.4.7 輸出156 7.4.8 GPT與GPT-2的異同156 7.5 GPT-3簡介157 7.6 小結160 第8章 BERT的優化方法161 8.1 視覺化XLNet原理162 8.1.1 排列語言模型簡介162 8.1.2 使用雙流自注意力機制163 8.1.3 融入Transformer-XL的理念164 8.1.4 改進後的效果164 8.2 ALBERT方法164 8.2.1 分解Vocabulary Embeddi
ng矩陣165 8.2.2 跨層共用參數167 8.2.3 用SOP代替NSP方法168 8.2.4 其他優化方法169 8.3 ELECTRA方法170 8.3.1 ELECTRA概述170 8.3.2 RTD結構171 8.3.3 損失函數171 8.3.4 ELECTRA與GAN的異同172 8.3.5 評估172 8.4 小結173 第9章 推薦系統174 9.1 推薦系統概述174 9.1.1 推薦系統的一般流程174 9.1.2 常用推薦演算法175 9.2 協同過濾176 9.2.1 基於用戶的協同過濾176 9.2.2 基於物品的協同過濾177 9.3 深度學習在推薦系統中的應
用178 9.3.1 協同過濾中與神經網路結合178 9.3.2 融入多層感知機的推薦系統179 9.3.3 融入卷積網路的推薦系統180 9.3.4 融入Transformer的推薦系統181 9.4 小結183 第二部分 Embedding應用實例 第10章 用Embedding表現分類特徵186 10.1 專案背景186 10.1.1 項目概述186 10.1.2 資料集說明187 10.2 TensorFlow 2詳細實現188 10.2.1 導入TensorFlow和其他庫188 10.2.2 導入資料集並創建dataframe188 10.2.3 將dataframe拆分為訓練、
驗證和測試集189 10.2.4 用tf.data創建輸入流水線189 10.2.5 TensorFlow提供的幾種處理特徵列的方法190 10.2.6 選擇特徵193 10.2.7 創建網路的輸入層194 10.2.8 創建、編譯和訓練模型194 10.2.9 視覺化訓練過程195 10.2.10 測試模型196 10.3 小結197 第11章 用Embedding提升機器學習性能198 11.1 項目概述198 11.1.1 資料集簡介199 11.1.2 導入數據200 11.1.3 預處理數據201 11.1.4 定義公共函數203 11.2 使用Embedding提升神經網路性能20
5 11.2.1 基於獨熱編碼的模型205 11.2.2 基於Embedding的模型207 11.3 構建XGBoost模型211 11.4 使用Embedding資料的XGBoost模型212 11.5 視覺化Embedding數據213 11.6 小結215 第12章 用Transformer實現英譯中216 12.1 TensorFlow 2+實例概述216 12.2 預處理數據217 12.2.1 下載數據217 12.2.2 分割數據219 12.2.3 創建英文語料字典220 12.2.4 創建中文語料字典222 12.2.5 定義編碼函數222 12.2.6 過濾數據223 1
2.2.7 創建訓練集和驗證集223 12.3 構建Transformer模型225 12.3.1 Transformer模型架構圖225 12.3.2 架構說明226 12.3.3 構建scaled_dot_product_attention模組226 12.3.4 構建MultiHeadAttention模組227 12.3.5 構建point_wise_feed_forward_network模組228 12.3.6 構建EncoderLayer模組228 12.3.7 構建Encoder模組229 12.3.8 構建DecoderLayer模組230 12.3.9 構建Decoder模
組231 12.3.10 構建Transformer模型232 12.3.11 定義遮罩函數233 12.4 定義損失函數236 12.5 定義優化器237 12.6 訓練模型239 12.6.1 產生實體Transformer239 12.6.2 設置checkpoint239 12.6.3 生成多種遮罩240 12.6.4 定義訓練模型函數240 12.6.5 訓練模型241 12.7 評估預測模型242 12.7.1 定義評估函數242 12.7.2 測試翻譯幾個簡單語句243 12.8 視覺化注意力權重243 12.9 小結245 第13章 Embedding技術在推薦系統中的應用24
6 13.1 Embedding在Airbnb推薦系統中的應用246 13.2 Transformer在阿裡推薦系統中的應用249 13.3 BERT在美團推薦系統中的應用250 13.4 小結253 第14章 用BERT實現中文語句分類254 14.1 背景說明254 14.1.1 查看中文BERT字典裡的一些資訊255 14.1.2 使用tokenizer分割中文語句256 14.2 視覺化BERT注意力權重256 14.2.1 BERT對MASK字的預測256 14.2.2 導入視覺化需要的庫257 14.2.3 視覺化258 14.3 用BERT預訓練模型微調下游任務259 14.3.
1 準備原始文本資料259 14.3.2 將原始文本轉換成BERT的輸入格式260 14.3.3 定義讀取資料的函數261 14.3.4 讀取資料並進行資料轉換263 14.3.5 增加一個批量維度264 14.3.6 查看一個批次數據樣例265 14.3.7 微調BERT完成下游任務265 14.3.8 查看微調後模型的結構266 14.4 訓練模型267 14.4.1 定義預測函數267 14.4.2 訓練模型268 14.5 測試模型269 14.5.1 用新資料測試模型269 14.5.2 比較微調前後的資料異同270 14.5.3 視覺化注意力權重271 14.6 小結272 第15
章 用GPT-2生成文本273 15.1 GPT-2概述273 15.2 用GPT-2生成新聞275 15.2.1 定義隨機選擇函數275 15.2.2 使用預訓練模型生成新聞275 15.3 微調GPT-2生成戲劇文本277 15.3.1 讀取文件277 15.3.2 對檔進行分詞277 15.3.3 把資料集轉換為可反覆運算對象278 15.3.4 訓練模型278 15.3.5 使用模型生成文本279 15.4 小結280 第16章 Embedding技術總結281 16.1 Embedding技術回顧281 16.1.1 Embedding表示281 16.1.2 多種學習Embeddi
ng表示的演算法282 16.1.3 幾種Embedding衍生技術283 16.1.4 Embedding技術的不足285 16.2 Embedding技術展望285 16.2.1 從Embedding的表示方面進行優化285 16.2.2 從Embedding的結構上進行優化286 16.3 小結286 附錄A 基於GPU的TensorFlow 2+、PyTorch 1+升級安裝287 附錄B 語言模型307