網路加速器的問題,透過圖書和論文來找解法和答案更準確安心。 我們找到下列各種有用的問答集和懶人包
網路加速器的問題,我們搜遍了碩博士論文和台灣出版的書籍,推薦AI4kids 寫的 淺談邊緣運算:智慧生活大趨勢(學AI真簡單系列6) 和劉峻誠,羅明健 的 深度學習:硬體設計都 可以從中找到所需的評價。
另外網站網路加速器免費 - Merisa也說明:網路加速器 – cFosSpeed,封包最佳化的電腦網路加速器,利用類似於QoS工作原理的流量塑形技術,對網際網路封包進行重新排序,首先傳輸高優先封包,以降低網路延遲,提高 ...
這兩本書分別來自全華圖書 和全華圖書所出版 。
國立臺灣科技大學 電機工程系 陳雅淑所指導 楊為屹的 提高可變電阻式記憶體神經網路加速器之利用率與能效的排程方法 (2021),提出網路加速器關鍵因素是什麼,來自於Neural network acceleration、Processing-in-memory、ReRAM crossbar array。
而第二篇論文國立中正大學 資訊工程研究所 林泰吉所指導 黃教銓的 具備AI 加速器之RISC-V 微處理器 之MLPerf Tiny 效能評估 (2021),提出因為有 MLPerf Tiny測試基準的重點而找出了 網路加速器的解答。
最後網站外貿專用網路加速器,極致網遊加速器 - M頭條則補充:極致網遊加速器於2005年正式成立,至今有多年從事此行業經驗,現已成國內技術最先進虛擬專用網提供商之一極致網遊加速器支援: 中國臺灣香港韓國日本 ...
淺談邊緣運算:智慧生活大趨勢(學AI真簡單系列6)
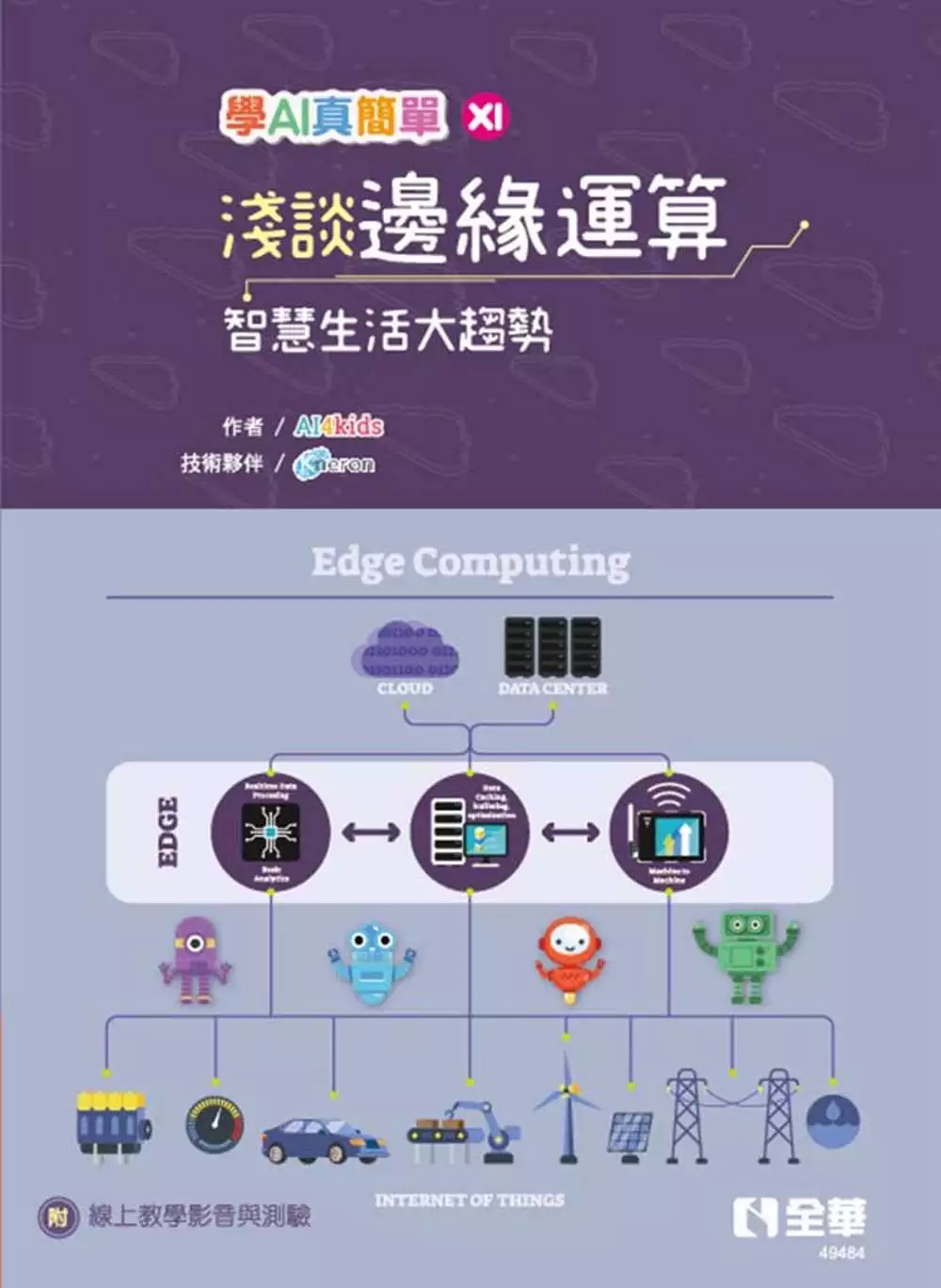
為了解決網路加速器 的問題,作者AI4kids 這樣論述:
本書透過簡單易懂的用語,以及大量的圖文解說,帶領讀者探索你我身邊最常見的AI應用──邊緣運算。從物聯網(IOT)的發展到加入AI元素的AIoT這段歷程,究竟是如何發生?這些改變又將帶給人們生活什麼樣的衝擊與改變?讀者都可在這本書中一窺究竟。AI學習不再流於理論空談。作者將實際操作的範例一步步詳細解說,帶領讀者親自動手實作邊緣運算中最常見的影像辨識系統,並整合樹莓派(微電腦)與最新神經網路加速器設備(NPU),加速推論過程的實現。 本書作者為AI4kids團隊,曾應教育部國教署邀請,至全國高中主任會議分享AI教學、親子天下雜誌專文報導,成員來自AIA台灣人工智慧學校
的校友,團隊有軟體技術、創新研發、工程管理、電商行銷等資歷專長,因為對AI科技教育的熱情而投入AI的教案研發與教學,目標是透過教孩子動手實作AI專題,來啟發他們對好奇心與想像力,協助他們運用各種程式或平台工具來探索、創造自己的AI應用。 本書特色 讀得懂:全彩圖文解說,激發讀者興趣、接軌AI應用。 好理解:步驟性的詳述,操作畫面清楚、理解範例容易。
網路加速器進入發燒排行的影片
好康加碼別錯過!透過客服管道(https://n-warp.com/r/member/issue-create)
說明「實況主DuckHugh推薦」,即可額外再獲得30天遊戲加速!
#nwarp #網路加速 #路由優化器
提高可變電阻式記憶體神經網路加速器之利用率與能效的排程方法
為了解決網路加速器 的問題,作者楊為屹 這樣論述:
電阻式記憶體成為加速嵌入式系統中神經網路推理的新興解決方案。為了减少神經網路的延遲,所有預先訓練好的權重會先寫入在電阻式記憶體中,以執行神經網路的推理階段。 然而,由於部署的神經網路數據依賴性,常導致低系統利用率,並浪費能耗。本論文中,我們提出了一種排程引擎,用於提高基於電阻式記憶體的加速器之利用率和能源效率。我們提出的排程引擎通過延遲推理運算的起始時間與運行時的權重寫入,回收空閒時間,進而提高能源效率以及資源利用率。相較於通過權重複製於多個記憶體單元來避免空閒時間,排程引擎能够在有限資源下執行多個神經網路,進而提升系統利用率和能源效率。實驗結果表明,與現有基於電阻式記憶體的加速器相比,搭配
本論文提出的排程引擎最多可降低50%的耗能,以及提升37%的效能。
深度學習:硬體設計

為了解決網路加速器 的問題,作者劉峻誠,羅明健 這樣論述:
深度學習成功解決許多電腦上的難題,並廣泛應用於日常生活中,例如:金融、零售和醫療保健等。本書從中央處理器(CPU)、圖形處理器(GPU)和神經網路處理器(NPU),到各種深度學習硬體設計,並列出解決問題的不同方式。 從這些設計中,可以發展出嶄新硬體設計,進一步改善整體效能和功耗,而本書有說明新的硬體設計,即流圖理論和三維神經處理,並提出智能機器人項目,以耐能終端智慧加速器(Kneron Edge AI)提升深度學習成效,其具有低成本的優勢,並以較低的功耗,實現較佳的性能。 本書適用於大學、科大資工、電子、電機、自控系「深度學習」課程及對本書有興趣的人士使用。 本書特
色 1. 本書針對目前深度學習在解決算力瓶頸的架構,獨家收錄包括各家IC設計與個別實驗室的設計。 2. 針對不同的架構有深入淺出的說明,並輔助使用大量的圖示,以資料流的路徑觀點,說明設計的優缺點。 3. 本書專題包含有趣的自駕車與無人機。 4. 本書獨家與耐能智慧科技合作,使用耐能智慧科技的AI Dongle,並代以實際的例子做說明,利用實作專題的方式,讓本書的讀者可以認知AI EDGE晶片設計架構所帶來的好處。 5. 本書在每個章節提供反思的練習題,幫助讀者能正確的理解。
具備AI 加速器之RISC-V 微處理器 之MLPerf Tiny 效能評估
為了解決網路加速器 的問題,作者黃教銓 這樣論述:
MLPerf Tiny 是目前嵌入式系統評估AI 效能之常用工具。本論文首先介紹MLPerf Tiny 之benchmark programs 及測試基準,並重現公開平台之相關測試數據。接著,本論文將以相同流程評估中正大學射月計畫產出之智慧音訊SoC。我們將以硬體加速器實現之功能以函式庫方式實作,可輕易移植至不同之AI 加速嵌入式系統進行效能評估。